
Release information: SILVA 138 SSU
Release information of the SILVA SSU database 138 as of December 16, 2019
| SSU 138 | LSU | |||
|---|---|---|---|---|
| Parc | 9,469,656 | (+ 3,396,475) | tbd | |
| Ref | 2,225,272 | (+ 134,604) | tbd | |
| Ref NR 99 | 510,984 | (- 184,187) | tbd | |
Since release 115, for SSU only SSU Ref NR 99 contains a guide tree.
Former statistics:
 SILVA 95, Silva 96, SILVA 98, SILVA 100,
SILVA 95, Silva 96, SILVA 98, SILVA 100, ![]() SILVA 102,
SILVA 102, ![]() SILVA 104, SILVA 106, SILVA 108, SILVA 111, SILVA 115, SILVA 119, SILVA 123, SILVA 128, SILVA 132
SILVA 104, SILVA 106, SILVA 108, SILVA 111, SILVA 115, SILVA 119, SILVA 123, SILVA 128, SILVA 132
Small Subunit rRNA Database
SSU Parc (Web database only) contains all aligned sequences with an alignment identity value equal and above 50, an alignment quality value equal and above 40 as well as an basepair score or sequence quality equal and above 30. All sequences with a Pintail value < 50 or an alignment quality value < 75 have been assigned to color group 1 in ARB (red). All Living Tree Project or ![]() StrainInfo typestrains have been assigned to color group 2 in ARB (light blue). No further sequence curation has been applied.
StrainInfo typestrains have been assigned to color group 2 in ARB (light blue). No further sequence curation has been applied.
To create SSU Ref (Web database & ARB file), all sequences below 1,200 bases for Bacteria and Eukarya and below 900 bases for Archaea or an alignment identity below 70 or an alignment quality value below 50 have been removed from SSU Parc. All sequences with a Pintail value < 50 or an alignment quality value < 75 have been assigned to color group 1 in ARB (red). All Living Tree Project or ![]() StrainInfo typestrains have been assigned to color group 2 in ARB (light blue).
StrainInfo typestrains have been assigned to color group 2 in ARB (light blue).
To create SSU Ref NR 99 (Web database & ARB file), a 99% identity criterion to remove highly identical sequences was applied using the  vsearch tool with a custom sequence order first based on presence in the last release's Ref NR 99 and second based on combination of sequence length (weighted twofold) and quality. For the sorting, the quality of a sequence is determinded by ambiguties (50%), overall alignment quality (45%), and homopolymers (5%). The overall alignment quality of the sequence is calculated from its alignment score, alignment identity, and alignment percentage (all equally weighted). Sequences from cultivated species have been preserved in all cases. Detailed information about the SSU Ref NR dataset can be found here.
vsearch tool with a custom sequence order first based on presence in the last release's Ref NR 99 and second based on combination of sequence length (weighted twofold) and quality. For the sorting, the quality of a sequence is determinded by ambiguties (50%), overall alignment quality (45%), and homopolymers (5%). The overall alignment quality of the sequence is calculated from its alignment score, alignment identity, and alignment percentage (all equally weighted). Sequences from cultivated species have been preserved in all cases. Detailed information about the SSU Ref NR dataset can be found here.
A guide tree was calculated by adding all sequences to the SSU Ref tree of SILVA release 132. For tree calculation, highly variable positions were removed for Bacteria, Archaea, and Eukarya with the respective position variability filters. Position variability filters for Bacteria, Archaea and Eukarya have been calculated and added to the dataset. The tree was extensively manually curated taking into account the latest taxonomic information. More information about the SILVA and LTP taxonomic frameworks can be found in the respective paper.
Remark: Before using the alignment for extensive phylogenetic reconstructions all sequences should be checked carefully.
Large Subunit rRNA Databases
LSU Parc (Web database & ARB file) contains all aligned sequences with an alignment identity value equal and above 40 and an alignment quality value, a basepair score or a sequence quality equal and above 30. All sequences with an alignment quality value < 75 have been assigned to color group 1 in ARB (red). All ![]() Living Tree Project or
Living Tree Project or ![]() StrainInfo typestrains have been assigned to color group 2 in ARB (light blue). No further curation has been applied.
StrainInfo typestrains have been assigned to color group 2 in ARB (light blue). No further curation has been applied.
Additionally, for LSU Ref (Web database & ARB file) all sequences below 1,900 bases or an alignment identity below 60 have been removed. The process to create LSU Ref NR 99 (Web database & ARB file) from the LSU Ref is analogous to the creation of the SSU Ref NR99 (see above).
Please take into account that the LSU SEED consists only of around 4508 sequences and there is no guaranty that well aligned close relatives have always been available. We would recommend additional manual curation before using it for extensive phylogenetic reconstructions.
Taxonomies, Names, Type Strain & Genome Information
Taxonomy
With SILVA release 102 the default taxonomy shown on the webpage (browser/search) is the SILVA taxonomy. Briefly, the tree for Bacteria and Archaea has been organized based on the Bergey's taxonomic outline, LPSN and the literature. Starting with SILVA release 111, extensive care has been taken to also improve the eukaryotic taxonomy. From SILVA release 138 on, the Genome Taxonomy Database (GTDB) and UniEuk taxonomies are used as additional resources for the curation. Based on the curated SILVA Ref NR taxonomy all sequences in SILVA (Parc) have been automatically classified.
Alternative Taxonomies
Besides the SILVA and EMBL-EBI/ENA taxonomy, alternative classifications taken from the GTDB (June 2019), RDP II (July 2017) and LTP (SSU June 2017, LSU September 2015) projects are also available in SILVA. On the webpage, the user can switch using the taxonomy menu. In ARB, the different taxonomies can be found in the fields: tax_slv, tax_embl, tax_gtdb, tax_rdp and tax_ltp for SILVA, EMBL-EBI/ENA, GTDB, RDP II and LTP, respectively. The corresponding *_name fields shows the respective sequence name for each entry. Please take into account that greengenes, RDP II and LTP provide only a subset of the sequences hosted by SILVA. If no taxonomic mapping to greengenes, RDP II or LTP was available they are assigned as "unclassified" and the respective sequence name equals EMBL-EBI/ENA.
Altenative Names
All names of validly described species in the SSU and LSU databases have been checked for changes (basonyms, synonyms and orthographical corrections) against the DSMZ "Bacterial Nomenclature up to date (PNU)" service as of June 2019.
Cultured and Type strains
The information if a sequence originates from a cultured or type strain has been added to the field strain and is indicated by [T] and [C]. Several sources have been used to compile the information: The  StrainInfo.net bioportal (July 2017), The Ribosomal Database Project II (July 2017) and the Living Tree Project (SSU release 132, LSU release 123) which provides manually curated information compliant with Euzebys "List of Prokaryotic names with Standing in Nomenclature".
StrainInfo.net bioportal (July 2017), The Ribosomal Database Project II (July 2017) and the Living Tree Project (SSU release 132, LSU release 123) which provides manually curated information compliant with Euzebys "List of Prokaryotic names with Standing in Nomenclature".
Genomes
The information if a sequence originates from a genome project has been taken from NBCI and added to the field strain. It is indicated by n[G] and w[G] for genomic entries reported in the WGS section of INSDC.
Detailed information about the corresponding identifiers and target databases can be found in the table to the right.
The identifiers can be used for data retrieval by searching in the strain field see FAQ.
Quality Values
The length and colours of the bars give a first indication on the sequence and alignment quality as well as the risk for sequence anomalies based on Pintail analysis. After downloading the sequences as an ARB file, sequences that need attention can be selected by searching for low quality (alignment, sequence) or Pintail values in the corresponding ARB database fields. A full description of the colour code and all database fields available in the ARB files can be found in the FAQ section. Taking into account the rich set of sequence associated information that comes along with every SILVA sequence, user designed sub-databases can be easily generated.
SEEDs
All rRNA sequences have been aligned based on a completely manually re-checked SEED alignment of 67,342 rRNA sequences for SSU and 4508 rRNA sequences for LSU. The SSU alignment is based on the official ssu_jan04 release of the ARB Project. The SSU SEED alignment has been considerably improved for Archaea by manual addition of more than 1,000 sequences as well as Fungi (10,000 sequences). All SSU Eukaryotic sequences (18S) have been cross-checked by Wolfgang Ludwig before their addition to the SEED. Most of the bacterial sequences have also undergone a curation process carried out by the SILVA Team. We would rate our SSU SEED alignment for all Bacteria and Archaea as good and for Eukarya as reasonable.
The LSU alignment was provided by Wolfgang Ludwig and has not been released before SILVA. It was cross-checked by the SILVA Team before using it as the SEED for automatic alignment. Bacteria and Archaea could be rated as good. The Eukaryotes need definitely further attention. With SILVA release 128 the LSU SEED has been significantly expanded by the integration of the LSU LTP sequences (1217) and curated sequences from Fungi (1587) thanks to Katrin Panzer and Marlis Reich.
Statistics
SILVA Ref NR Changes (reduced size)
The SILVA 138 SSU Ref NR 99 contains fewer sequences compared to previous releases.
We decided to switch from an old version of UCLUST (1.0.50; reference to the UCLUST implementation in USEARCH) to a recent version of VSEARCH (2.13) which increases clustering performance and will, hopefully, allow us to provide a more stable Ref NR (in terms of reference sequences) in the future.
The reduced size of the Ref NR is caused by the two tools using a different definition of sequence/alignment identity. We cross-checked the clustering results by using a third tool (CD-HIT v4.8). Given the same identity threshold, VSEARCH (using USEARCH's as well as using CD-HIT's definition of sequence/alignment identity) and CD-HIT report similar clusters whereas the old version of UCLUST reports a 'significantly' larger number of clusters.
Sequence Retrieval and Processing
| SSU 138 | LSU | |
|---|---|---|
| candidates (total) | 13,044,369 | tbd |
| RNAmmer | 2,972,220 | tbd |
| < 300 bases | 2,659,189 | tbd |
| > 2% ambiguities | 36,696 | tbd |
| > 2% homopolymers | 191,630 | tbd |
| > 2% vector contamination | 2,206 | tbd |
| low alignment identity | 810,792 | tbd |
total rejected by QC | 3,574,710 | tbd |
Sequences have been retrieved from EMBL-EBI/ENA Release 138 (November 2018) using a complex keyword search procedure and sequence based search with RNAmmer profiles. Cross checks with RDP II indicated no loss of primary data. Most of the sequences rejected by a low identity value after alignment with SINA were classified as not ribosomal RNA sequences by manual inspection.
1. Growth of the ribosomal RNA databases since 1992
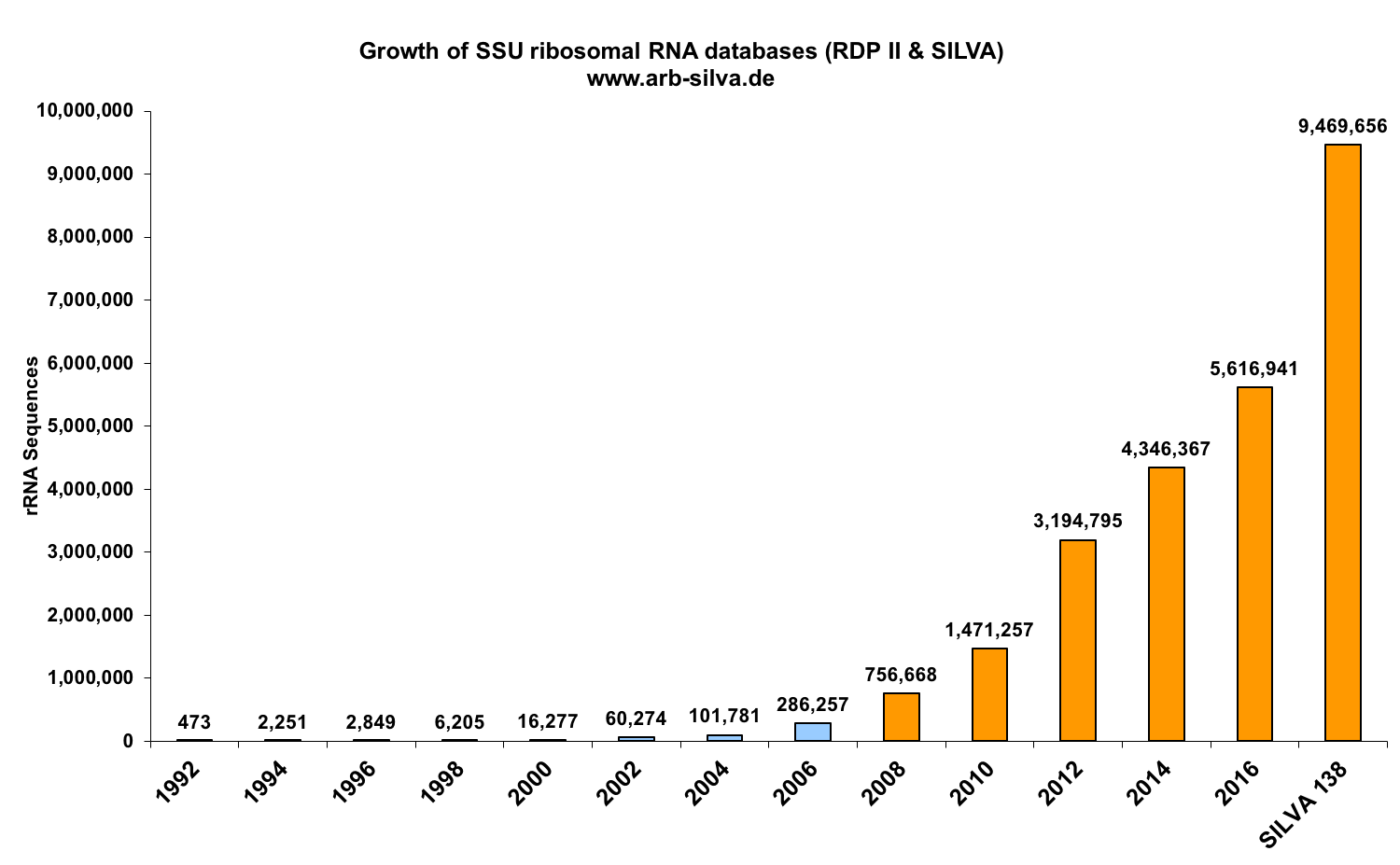
Blue: RDP II, orange: SILVA SSUParc based on EMBL releases
2. Length Distribution (SSU)

Blue: raw data, red: the quality checked & aligned SSU Parc
Basic statistics for the SILVA databases
| SSU Ref | SSU Ref NR | LSU Ref | LSU Ref NR | |
|---|---|---|---|---|
| Version | 138 | 138 | tbd | tbd |
| Total | 2,225,272 | 510,984 | tbd | tbd |
| Bacteria | 1,983,534 | 431,785 | tbd | tbd |
| Archaea | 69,198 | 20,389 | tbd | tbd |
| Eukaryota | 172,540 | 58,810 | tbd | tbd |
| Cultured | 39,316 | 39,316 | tbd | tbd |
| Typestrains | 24,444 | 24,441 | tbd | tbd |
Strain Identifiers
| Source | Information | Tag | Datasets |
|---|---|---|---|
| NCBI | Genomes | n[G] | SSU, LSU |
| NCBI | WGS genomes | w[G] | SSU, LSU |
| Straininfo.net | Cultured | s[C] | SSU, LSU |
| Straininfo.net | Typestrains | s[T] | SSU, LSU |
| Living Tree Project | Typestrains (curated) | l[T] | SSU, LSU |
| RDP II | Typestrains | r[T] | SSU |
RNAmmer
RNAmmer is a computational predictor for the major rRNA species (SSU, LSU) from all three domains of life. The program uses hidden Markov models trained on data from the European ribosomal RNA database project. SILVA runs the profiles of RNAmmer on all sequence entries of the EMBL-EBI/ENA archive to complement the existing predictions. All predictions are marked with RNAmmer in the ann_src_field. More information about RNAmmer can be found in the paper.
New in Release 138
- Webpage
- ARB files
- The clustering procedure of the SILVA Ref NR (non redundant) 99 dataset has been changed to enhance the stability of the NR subset
- The clustering procedure of the
- Pipeline
- several improvements and bug fixing
- changed clustering tool to vsearch
- use quality-based sorting for clustering
- genome information is now imported from NCBI (was EMBL)
- "Bacterial Nomenclature Up-to-date (PNU)" database is now consitently used across SILVA
- GTDB taxonomy is imported as alternative taxonomy
- Taxonomy
- Major taxonomy upgrade: 2/3 of all SILVA taxonomic paths have changed.
- Extensive adoption of the Genome Taxonomy Database, LPSN, Bergey's and UniEuk taxonomies with special focus in orders, classes and phyla.
- Abundant modifications can be expected in the following groups: Archaea, Enterobacterales, Deltaproteobacteria, Firmicutes, Clostridia.
- Betaproteobacteriales (formerly known as Betaproteobacteria) is now Burkholderiales, an order of Gammaproteobacteria.
- Epsilonproteobacteria vanishes within a new phylum Campilobacterota.
- Tenericutes gone. They are all part of Bacilli, inside Firmicutes.
- Several errors in the bacterial, archaeal and eukaryotic taxonomy have corrected.
- General tree cleanup to remove anomalies.
- Clean up of suspect bad quality/chimeric sequences.
Known Bugs
- SSU Parc: 211,240 sequences have no Pintail values
Citations

Quast C, Pruesse E, Yilmaz P, Gerken J, Schweer T, Yarza P, Peplies J, Glöckner FO (2013) The SILVA ribosomal RNA gene database project: improved data processing and web-based tools. Nucl. Acids Res. 41 (D1): D590-D596.
Yilmaz P, Parfrey LW, Yarza P, Gerken J, Pruesse E, Quast C, Schweer T, Peplies J, Ludwig W, Glöckner FO (2014) The SILVA and "All-species Living Tree Project (LTP)" taxonomic frameworks. Nucl. Acids Res. 42:D643-D648
If you use SINA please cite:
Pruesse, E, Peplies, J and Glöckner, FO (2012) SINA: accurate high-throughput multiple sequence alignment of ribosomal RNA genes. Bioinformatics, 28, 1823-1829